

Our step-by-step guide to applying the concept of relative sizing to estimation continues. In this section we’ll build backlogs at various levels of detail – from high level product road maps, through release planning, and onward with increasing levels of precision all the way down to detailed iteration planning…
If you haven’t read Part 1 yet, please go back and make sure you understand the relative sizing concepts introduced there.
High-Level Estimates
Remember that (most of the time) our ultimate goal in estimation is to provide a cost estimate, and/or validate our ability to meet a deadline. We are often asked to provide these data points before we even know a lot about the requested deliverable. In the traditional world, high level estimates are often created by comparing a new piece of work with past pieces of work. We figure out how big the old thing turned out to be, then assume this new thing is approximately the same size, plus or minus some pre-negotiated margin of error!
High Level estimation, a.k.a. Rough-Sizing or T-Shirt Sizing is done when we know the least about the work being proposed. Therefore, we accept that our Accuracy will probably be way off. This level of estimation is generally presented as having a precision of +/- 50%.
What do you apply these estimates to? Features or Epics – generally large units of work that we’d expect to take the team more than one iteration to complete.
When is it appropriate to use this level of estimation? At the beginning when we know the least.
How will we use this level of estimation? Well for one thing, we can use it to create a high-level roadmap. The Product Roadmap provides a rough idea of whether it is possible to deliver a body of work in a given timeframe, and to provide a rough idea of the sequence of delivery.
Units of Measurement: T-Shirt sizes (XS, S, M, L, XL, XXL, etc…) <- Note, this is a shorthand nomenclature that doesn’t equate to cost or time (yet). More on that in a bit…
As a measurement of relative size, it is more important to understand the relationship between the T-Shirt sizes. We will employ a simple rule. Each subsequent T-Shirt size doubles the previous one. Thus, if we were to equate “Small” is equivalent to the amount of work in 1 Sprint, then “Medium” is twice that amount of work (2 Sprints), and a “Large” is double the medium (4 Sprints). See Figure 2.1.
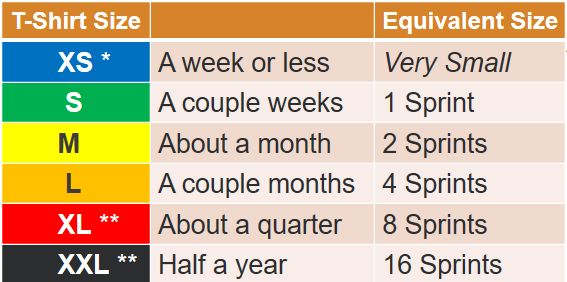
This example assumes two-week Sprints
Mid-Level Estimates
Size estimation a.k.a. Story Sizing, Story Pointing, Fibonacci, is done when the team has had a chance to understand the Epics/Features, and are now taking part in the decomposition of these larger deliverables into well-understood, bite-sized units of work that can each be delivered within a single iteration. These size estimates are generally accepted to have a precision of +/- 25%
The most common scale used in Story Point sizing is the Fibonacci sequence. If you remember back to your school days, the Fibonacci Sequence is defined as a sequence of numbers in which each number in the sequence is the sum of the two previous values: 1, 1, 2, 3, 5, 8, 13, 21, 34, etc… Fibonacci allows us to correct for another oddity in human perception. When we start talking about relative size, identifying things that are double and triple in size are pretty straightforward. But as things get bigger and bigger, we have a tendency to compress them in our minds. Such that it is virtually impossible to distinguish whether something is 9,10, or 11 times the size of another thing. You can see how hard that would be, right? Now imagine arguing whether something is 36 or 37 times the size of another thing! By adopting the Fibonacci sequence, we’re introducing a distinction between values that’s pretty significant. I may not be able to distinguish between 9 and 10, but I can still make a distinction between 8, 13 and 21.
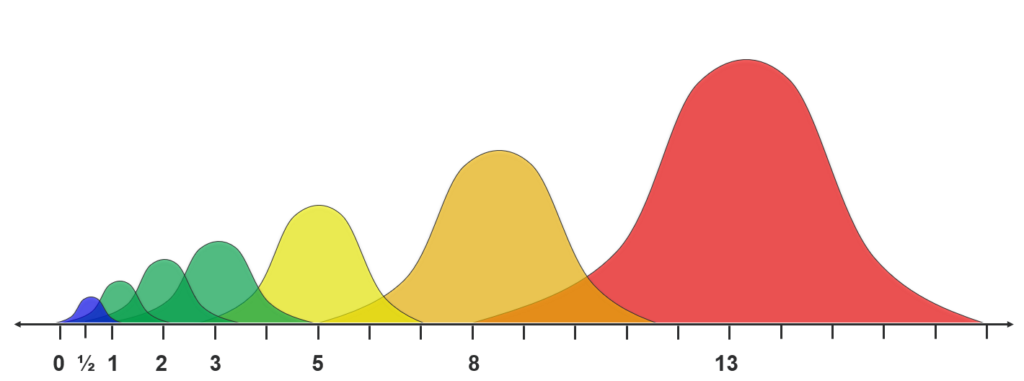
We can also leverage this phenomenon to keep our range of values contained. Lower values are easier to comprehend, therefore have a lower level of uncertainty. The greater the range between two consecutive options the greater the degree of uncertainty. So, accuracy and precision can both improve by shifting to Story Points, AND selecting reference sizes that will keep your individual estimates on the smaller side.
Building a Product Roadmap
The purpose of a product roadmap is to establish a rough idea of what’s possible over a longer term. To accomplish this, the Product Owner needs to gather the Development Team and any SMEs who would have expertise in the area being developed.
Sequence of Events
- The Product Owner presents the list of major features to the team. The team asks clarifying questions with the intent of figuring how much effort will be involved in creating that feature.
- The team was encouraged to ask questions to try to gain an appreciation for the magnitude of the work involved.
- While that discussion was going on, an index card was created to represent that feature.
- The team was then asked to place the feature card on the table in sorted order (smallest on the left, largest on the right). The first card is just placed in the center of the table, with things being placed by being bigger, smaller or about the same. Cards are shifted to make room as necessary.
- We now had a simple-sort of features arrayed from smallest to largest.
- Starting at the smallest Features, we had a discussion of how big those items were. “Did the team think those items could be completed in a couple days? (no) How about a couple weeks? (yes). Since this is one of our smallest work items, and it will take one or more sprints, we appear to have a bunch of Epics.”
- This is the first point where the team injected their understanding of size into their estimate.
- So, now we asked about the cards that were near this one on the table. If you think this smallest Epic is a couple weeks of work, follow the sorted line until you get to one that is no longer in that neighborhood. Everything to the left of that story is in the same size category. Let’s call those “Smalls”.
- The determination of the Smallest thing is key to relative sizing. At this point, it’s important to shift the team away from thinking explicitly about duration, but to think instead about magnitude of work. They are asked to think about the collection of Small Epics, and what they know about them. Now we ask them to imagine what twice that amount of work would feel like.
- With this image of ‘twice as large’ firmly in mind, start with that story they identified as the first epic beyond Small. “Does this epic feel like it is less than double the amount of work of the Smalls? (yes). Then this will be our first “Medium” epic. “Let’s go back to the line of cards and identify the others that are close to that size.” The first one that is more than double the Small, is a Large. Everything that falls between the last Small, and the first Large is “Medium”. We mark all the Mediums, and now doubling again, find all the epics that are “Large”, then doubling again, all those that are X-Large.
At that point, we had Epics grouped in doubling clusters. We can summarize this as follows:
- Small = 1 x (base) = 1 Sprint
- Medium = 2 x (base) = 2 Sprints
- Large = 4 x (base) = 4 Sprints
- X-Large = 8 x (base) = 8 Sprints
(base) was assumed to be “a couple weeks”
- We need to acknowledge that these estimates were made very quickly, with minimal information. We expect these estimates to have an uncertainty of +/- 50%
- The only thing we’re really sure about is that each subsequent group is a double of the previous.
- Assuming (base) is “a couple weeks” it is convenient to refer to (base) as “1 Sprint”. Note that this is only an ASSUMPTION! It is possible that everyone was uniformly optimistic. We won’t know for sure until they start working.
- The Team has a WIP limit of 3, so will concentrate their focus on no more than 3 Epics at a time — Dividing effort across multiple epics will increase the length of time it takes to deliver those Epics. So, not finishing a Small in “1 Sprint” doesn’t necessarily mean the estimate was wrong (it’s certainly a reason to investigate further).
- How much rework for Alpha defects are being addressed? Are they impacting development?
- How have we accounted for the loss of the tester? I know the devs are picking up the slack, but it stands to reason that’s going to slow down their progress from our base assumption.
- We’ve added developers, should our WIP limit assumptions shift too?
But if our assumption turns out to be false – what if it turns out base=3 weeks. Then our doubling can still help.
- Small = 1 x (3 weeks) = 1.5 Sprints
- Medium = 2 x (3 weeks) = 3 Sprints
- Large = 4 x (3 weeks) = 6 Sprints
- X-Large = 8 x (3 weeks) = 12 Sprints
Improving the Assumptions
Break the Epics into Stories, Size the Stories, Total the Sizes.
We tricked Jira into reflecting the Product Roadmap layout by saying that the Team’s assumed Velocity was 30, and in order to align that to show us a WIP limit of 3, we assigned sizes to our Epics in Jira in units of 10’s .
- Small = 10 SP
- Medium = 20 SP
- Large = 40 SP
- XLarge = 80 SP
Thus, 3 Small Epics with size of 10, worked on in a single Sprint, would deliver 30 points, matching our Velocity. Note that this conversion made Jira look like the spreadsheet, but that didn’t make it right!
In fact we quickly ran against the rocks when we started decomposing stories, and those stories totaled more points than the table above would indicate. That’s actually a good thing! If we just replaced the Story Point “Size” of each Epic with the sum total of the Stories beneath it, the Portfolio plug-in would adjust to accommodate that. Unfortunately, we made TWO tweaks … remember we adjusted expectations to provide a WIP limit. If the team’s velocity goes from 30 to 45, then the (base) assumption we’re making would change from 10 SP to 15 SP.