

Coach: “I’m concerned about the quality of delivery. The defect counts seem very high.”
Manager: “That’s why we have testers. To root out the defects.”
Coach: “I understand the value your testers are bringing. I’m referring to the frequency with which they bring it.”
Manager: “What difference does it make? The bugs are getting addressed.”
Coach: “The difference? It’s one thing to HAVE a safety net. It’s another thing to USE it.”
Real-Life Conversation
Imagine if you will…
The circus has come to town! At the appointed hour the tent flaps draw back and allow the waiting throng to file inside, filling the raised stands that surround the main ring. The sounds of a brass band fills the tent, setting the stage for the parade of performers filing in and around the ring. Clowns caper about, animals roar, the very air is full of electricity as the ringmaster announces the first act. The band cuts off, save for a single drummer executing the staccato of a perfect drum-roll.
Floodlights blaze to life, illuminating a platform perched high atop one of the towering tent polls. A taut wire connects this platform to its twin on a second pole far across the tent.
A tightrope walker stands atop the platform, illuminated by the xenon glare from the ground. The tension is palpable as the walker places one foot on the narrow wire, then quickly steps forward so both feet are now fully committed to what promises to be a death-defying stroll. The walker lifts their rear foot and brings it expertly forward to rest on the wire… and misses the mark.
Cries of shock and horror erupt from the crowd as the hapless performer plummets thirty feet and lands in the safety net below. Nonplussed, the performer swings down to the ground and climbs the pole again, once more perched to begin their harrowing journey. The drum rolls, they take a step, then another, and another, and a….woops!
Again, they drop from the sky, and into the net. For the next ten minutes the act continues. With every fall, the performer lands, reassuring the crowd that all is well, they ascend to the perch, walk across the rope, and plummet back into the net.
After a while, the crowd stops expressing concern. The pattern is familiar and routine. The thrill is no longer in whether the performer will fall, but rather how quickly. You glance at your watch and scan the crowd. People have pulled out their cellphones, their faces illuminated by tiny screens as they search for something to fill their time. Nobody is filming the performer. With each self-congratulatory landing in the net, the performer raises their hand in victory. By the time he actually makes it to the far platform, there is some half-hearted clapping, more an expression of relief that the next act can begin, than joy at the thrilling demonstration of skill that has just played out before them…
Back to Reality…
Coming back to reality, a high defect rate that you rely on your testers to find is a little like your developers taking dive after dive into the safety net. Your business partners – the nice folks who wrote the check that enabled your expert team to create the product in the first place are the increasingly disillusioned audience.
Thank goodness for the net, right?
This is the image that flashed in my mind as the manager from my opening conversation extolled the quality of his team’s work by expressing how awesome it was that the testers were finding all of these defects (albeit, a sprint later). He expressed how proud he was that the developers were taking time out of subsequent sprints of new development to fix the defects found in past work – time that spoke of their dedication to releasing a stable product to their users.
I tried again, “Aren’t you concerned about how many there are, though?”
“No,” he replied, “that’s why we have the testers. Surely you don’t want us to stop testing!”
“Of course not. I want the developers to stop creating the bugs. Don’t you?”
Quality?
Look, I get it. I spent 25 years banging out code myself. I would spend hours crafting a solution that met all the functional requests. Then I would submit my code to the build and move onto the next thing. Then, sometime later the tester would come knocking.
I’ll admit those were not happy conversations. I didn’t enjoy being told I had written something fragile and full of unintended functionality. At first indignance (‘you’re using it wrong’), then denial (‘it works on my machine’), then embarrassment (‘oh, come on, seriously?’), and finally, acceptance that maybe there was something I could have done to make it better. Realization that maybe, I could take a little more care before handing it off to the tester.
What I am advocating for, is that the developers should be taking pride in their work, to the point that they try to decrease the number defects the testers find. But it’s probably not as simple as that.
Getting to the root of the issue is required, and for that we’re going to need some frank discussion in a retrospective. There are a lot of potential root causes, and as easy as it may be to accuse the developers of taking a blasé attitude toward quality, it wouldn’t be my first guess.
Like I said, when a tester shows up at your doorstep with a finding, it’s a little like a gut-punch. It catches you right in the ego. There tends to be additional factors at play.
Cost?
I’m sure you’re aware that the cost of fixing a defect increases the farther it is from its inception when found. The following graphic shows the relative magnitude of the cost of fixing a defect later and later in development. (I like this chart because it’s represented in percentages rather than hard dollars).
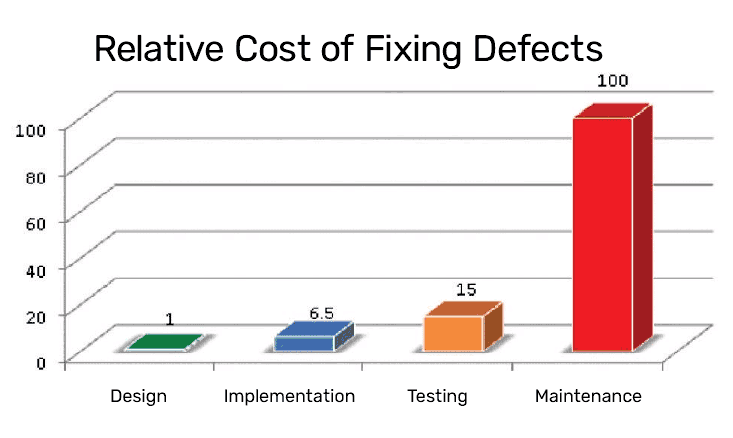
IBM System Science Institute Relative Cost of Fixing Defects
Using the cost of preventing the defect in the first place (in design) as a benchmark, finding that defect during implementation is 6.5 times more expensive to fix. But finding that same defect in testing is more than twice as expensive as that! Logically, that makes sense. Now you’re involving more than one person in the finding, reporting, fixing, redeployment, and revalidation steps.
Of course, it’s still leaps and bounds cheaper than the snowball effect associated with the customer finding the defect first! But still, does waiting for the programmer to face-plant into safety net seem as cost-effective now?
Flow
One of the reasons it’s more cost-effective to fix the issue closer to implementation has to do with the science of context-switching. When the developer was working on the code the first time, they were as in-the-moment as they could possibly be with the solution. By the time the tester finds the issue and reports back, the developer has already moved on to something else. They have to interrupt their current workflow, then get back in the mindset of that earlier piece of work, and then resume working in that older context.
Bottom Line
Anything that a team can do to remove defects earlier in the delivery process should be explored. Wherever your defects are being found now, explore what you can do to shift the detection to the left. Drawing folks from the step to the right into your conversations will help eliminate defects being found in that step. Bring the development team into the design discussions. Include the Testers in the Development discussions. Include the Customer in the validation discussions. Even one step to the left will create a cost savings.
By all means, we should keep the net. The net is a failsafe. The net catches us when something slips through our defenses. But relying on the net to find things we should have found sooner… Well, that’s just wasteful.